As I see it, the first criterion to pick a family medicine provider is vicinity, after which come others. Given that for Bucharest a proper map representation is not available, it seemed like a good opportunity to create a data set for the map created in a previous article.
I primarily use Typescript nowadays, so once I saw that there is no geolocation information in the excel file containing the list of family medicine providers, the first thought was to use nodejs. Therefore I quickly developed a plan to make a small application.
However, I had a change of heart after a quick chat with a friend of mine who is more into data where he suggested that I use Pandas and python. I haven’t used python in any project yet, but after seeing how much easier it would be, I realized it’s the perfect choice.
Related articles:
- https://draghici.net/2023/05/26/create-a-map-with-pois-using-react-leaflet-typescript-and-github/
- https://github.com/cristidraghici/geocoded-bucharest-family-medicine-providers
Prerequisites
We will try to keep the project as simple as possible, thus we will not use Docker for it. An operating system with python already installed should suffice. The python version is 3.10.11. To access the original excel file Libre Office has been used.
Disclaimer
This was the first time I used python, so the solution might not be the most optimal out there. Also, given the nature of the project – something that runs rarely to generate data that is saved to a file – I do not think spending much time in making the code pretty will have a good return on the investment. 😸
Preview
For creating a preview, I have used github pages, together with a previously created map published in the same service:
Python information
The is the first time I start from scratch with a python, project. Thus, there are some ideas that I might come in useful for another beginner:
- It is a well known fact that indentation is very important in python;
pip installwill not save the dependency to therequirements.txtfile, thus you have to run a different command:pip freeze > requirements.txt;- to install the requirements, use
pip install -r .\requirements.txt; - if you accidentally find yourself in the python console, you can type
quit()to exit; reworks slightly different than what I expected, given that I am a JS/TS dev, in this case being thatre.matchmatches from the start of the string, whilere.searchis the method to use when trying to find something inside the string.
Sources:
- https://note.nkmk.me/en/python-pip-install-requirements/
- https://stackoverflow.com/questions/19871253/re-match-returns-always-none
- https://csatlas.com/python-import-file-module/
The data source
To get the list of medicine providers in Bucharest, we can access the following URL: http://cas.cnas.ro/casmb/page/lista-cabinete-medicina-de-familie.html
At the time this article was written, the latest list was 20230721_Lista cabinete medicina de familie _20.07.2023.xlsx. Once opened with Libre office, we can perform a minimal cleanup of the file, namely:
- remove the lines at the top, with the title of the document;
- remove the styling for the whole document;
- moving the address column at the end of the columns, to easily check the parsed address against the original;
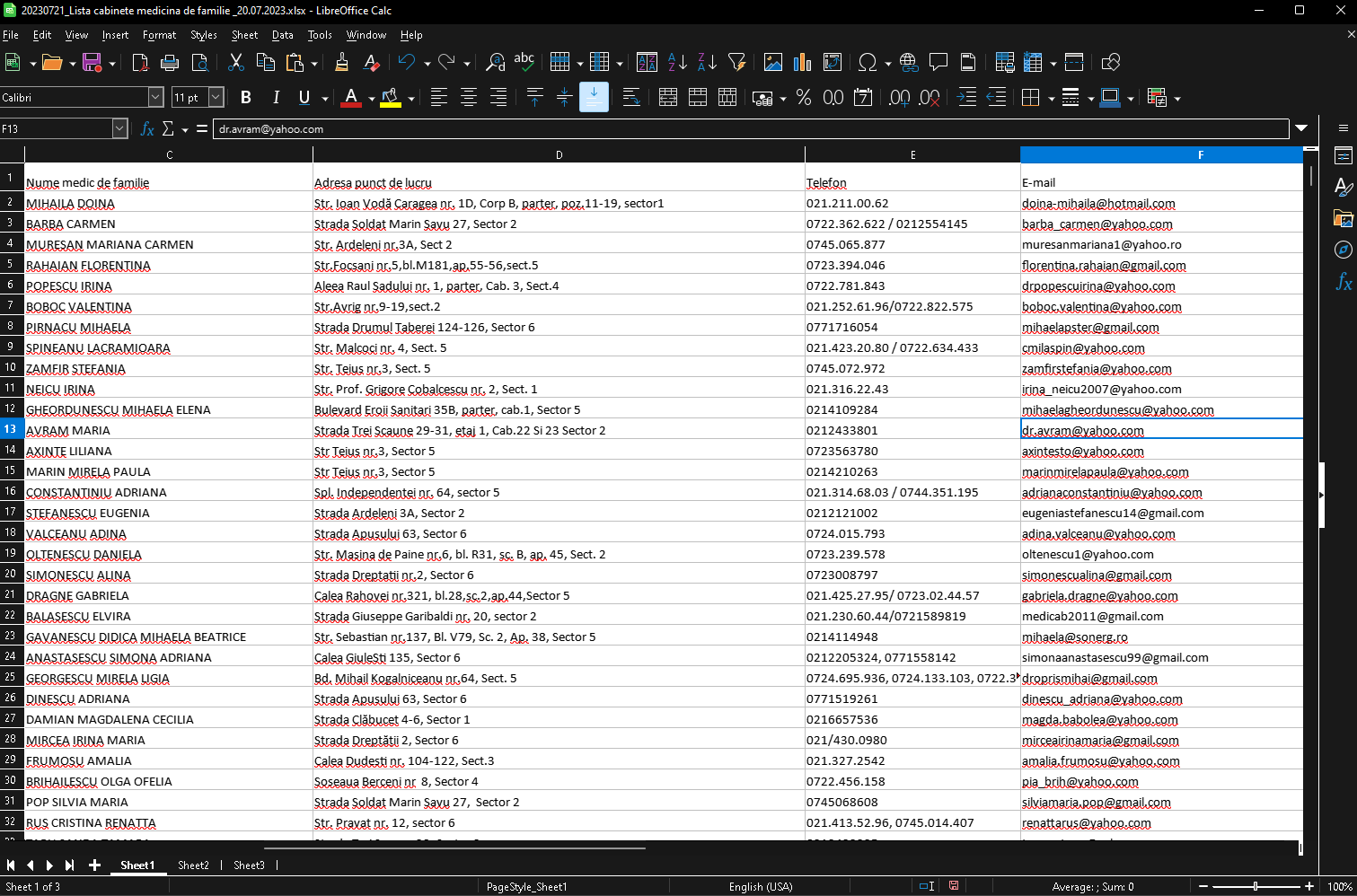
More info:
- https://ask.libreoffice.org/t/how-to-delete-unwanted-styles-and-formatting-options-in-libreoffice/4445
- https://help.libreoffice.org/6.3/en-US/text/scalc/guide/move_dragdrop.html?DbPAR=CALC
The parser
We will use a single python file for the script and just create one extra for utils functions. If performance issues are encountered, another approach could be to read, process and save chunks of data instead of the whole thing at once.
For now, though, script will consist of a few steps and a dev mode, which will be accessible via cli params:
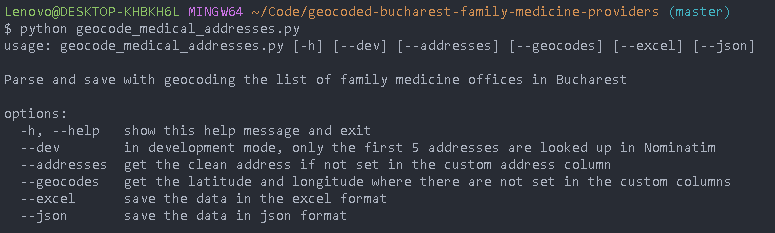
More info:
- https://docs.python.org/dev/library/argparse.html
- https://stackoverflow.com/questions/10698468/argparse-check-if-any-arguments-have-been-passed
Create the data set
The main issue we will encounter in adding geocoding information to each of the addresses is that the addresses are not in a standardized form. Google Maps seems to be quite smart about identifying an address from an unstructured string, but we aim to use open source tools and data.
For cleaning the data or adding new pieces of information, we will not directly use the excel file, but create a copy. This way, we will easily be able to start over if needed without having to manually cleanup the file again.
# Extract street and number from addresses
def extract_street_name_and_number(address):
# use alphanumeric characters
address = unidecode(address)
# ensure we have the proper prefix for the street
cleanupRegexList = [
# fix for number not separated
["nr", ", nr"],
# text cleanup (ensure there is a space at the end of the replace string)
[r"((?:Numarul\.|Numarul|Nr\.|Nr)\s|(?:Nr\.))", 'Numarul '],
[r"((?:Calea|Cal)\s|(?:Cal\.))", 'Calea'],
[r"((?:Calea|Cal)\s|(?:Cal\.))", 'Calea '],
[r"((?:Piata|Pta)\s|(?:Pta\.))", 'Piata '],
[r"((?:Drumul)\s)", 'Drumul '],
[r"((?:Strada|Str)\s|(?:Str\.|Stra\.))", 'Strada '],
[r"((?:Bulevardul|Bulevard|Bd|Bld|B-dul)\s|(?:Bd\.|Bld\.))", 'Bulevardul '],
[r"((?:Soseaua|Sos)\s|(?:Sos\.))", 'Soseaua '],
[r"((?:Splaiul|Spl)\s|(?:Spl\.))", 'Splaiul '],
[r"((?:Aleea)\s|(?:Al\.))", 'Aleea '],
[r"((?:Intarea|Int|Intr)\s|(?:Int\.|Intr\.))", 'Intrarea ']
]
for regex in cleanupRegexList:
address = re.sub(regex[0], f'{regex[1]} ', address, flags=re.I)
# commas and spaces
while ",," in address:
address = re.sub(r",,", ",", address)
while " " in address:
address = re.sub(r" ", " ", address)
address = re.sub(r" ,", ",", address)
address = re.sub(r", ", ",", address)
# get the street and number
returnAddress = ''
streetMatch = re.match(r"(Calea|Piata|Drumul|Strada|Bulevardul|Soseaua|Splaiul|Aleea|Intrarea)(.*?)(?:,)", address)
if (streetMatch):
returnAddress = ''.join(streetMatch.group(1, 2))
numberMatch = re.search(r"(Numarul )(.*?)(?:,)", address)
if (numberMatch):
returnAddress = f"{returnAddress}, {numberMatch.group(2)}"
# return the parsed address
return f"{returnAddress}, Bucuresti"Code language: PHP (php)A modern approach would be to use Open AI to ask which is the street and the number in the address string, and that would work. However, there are some minimal patterns and structure in the address, so a plain custom python function will help with most of the addresses.
We will go through the excel file row by row and add the output of the function to a new column, then run the function which tries to get the data from the OpenStreetMap address validator.
# Get coordinates using OSM
def validate_and_get_coordinates(geolocator, address):
try:
location = geolocator.geocode(address)
if location:
return location.latitude, location.longitude
else:
print(f"Location not available for '{address}'")
return None, None
except Exception as e:
print(f"Error occurred while validating address '{address}': {e}")
return None, NoneCode language: PHP (php)To prevent reaching the API limits for OSM, we will do the requests one by one and have a random delay between requests. Speed is not essential in this use case. The helper we will use is this:
from random import randint
from time import sleep
# Sleep for a random number of seconds, mainly to avoid hitting api limits
def random_delay(min, max):
sleep(randint(min, max))Code language: PHP (php)In the end, the row iterations will look like this:
if args.addresses:
# Parse the address and get an OSM searchable value (street name and street number)
for index, row in df.iterrows():
if pd.notna(row[address_column]):
street_name_and_number = utils.extract_street_name_and_number(row[address_column])
df.at[index, parsed_address] = street_name_and_number
if pd.isna(row[manual_address]):
df.at[index, manual_address] = street_name_and_number
if args.geocodes:
# Use OSM to get the latitude and longitude of each of the addresses
geolocator = Nominatim(user_agent='address_validator')
for index, row in df.iterrows():
address = row[manual_address]
if pd.isna(row['latitude']) or pd.isna(row['longitude']):
latitude, longitude = utils.validate_and_get_coordinates(geolocator, address)
if latitude is not None and longitude is not None:
df.at[index, 'latitude'] = latitude
df.at[index, 'longitude'] = longitude
print(f"Coordinates retrieved for address at {index}: {address}")
utils.random_delay(1, 3)
if args.dev and index == 5:
break
Code language: PHP (php)We will run the script with the command: python geocode_medical_addresses.py
Once the script is done, we will open the excel file and check the addresses one. We will manually modify the address where the latitude and longitude were not found. For this we will use use the OSM address search tool and we can also benefit from the sorting options Libre Office provides.
https://nominatim.openstreetmap.org/ui/search.html?q=Drumul+Taberei+124%2C+bucuresti
When we have updated all the rows, we will run the script again.
Save as JSON
We aim to use this data as the base of a map representation, for which we will use what we have previously built here:
The format aimed is a json with entities which look contain:
- title: string;
- description (optional): string or array of strings;
- latitude: number;
- longitude: number.
A sample of data is:
[
{
"title": "DOBRESCU DARIA",
"description": [
"Nr. Contract: A0005",
"Denumire furnizor: CMI DOBRESCU DARIA",
"Telefon: 021.111.10.63",
"E-mail: no.email@hotmail.com",
"Adresa punct de lucru: Str. Ioan Voda Caragea nr. 3, sector1"
],
"latitude": 44.4484363,
"longitude": 26.1009619
},
{
"title": "GHEORGHE ION",
"description": [
"Nr. Contract: A0013",
"Denumire furnizor: CMI GHEORGHE ION",
"Telefon: 0721.322.622 / 0214554345",
"E-mail: no-email@yahoo.com",
"Adresa punct de lucru: Strada Soldat Marin Savu 1, Sector 2"
],
"latitude": 44.441662,
"longitude": 26.1883371
}
]Code language: JSON / JSON with Comments (json)Publish to pages
Once the code is pushed to a github repository, it would be nice to have it published on a github page. This way, you will be able to use the url to see the points on the map: